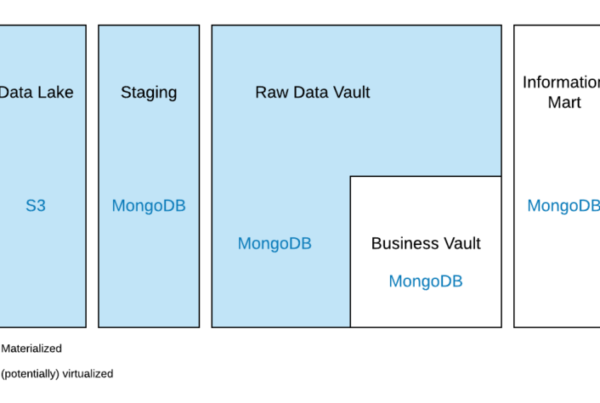
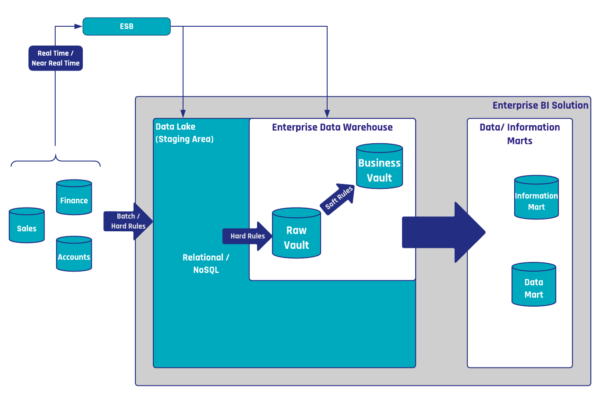
The previous articles within this series have presented hub and link entities to capture business keys as well as the relationships between business keys. To illustrate, the hub document collection in MongoDB is a distinct list of business keys used to identify customers.
As to capture the descriptive data, which in this case is the describing factor of the business keys, satellite entities are used in Data Vault. As both business keys and relationships between business keys can be described by user data, satellites may be attached to hub as well as link entities as such:

However, the way in which these Data Vault satellites are implemented within MongoDB varies in comparison to a Data Vault model on a relational database. First and foremost, there are satellite documents that describe a business key, or relationship. Though, because these changes can differ over time, the document is identified in the _id attribute by two sub-attributes: The _id of the business key, in this instance a hash key, and the ldts of the descriptive document:

The above document describes a customer and therefore it refers to the hash key hk_customer_h of the customer’s business key document, in this case a hub document.
Just as any other Data Vault document, it contains a rsrc attribute that identifies the source of data. That being so, the hd_customer_info_s is the hash diff of the document which is the hash value used to identify changes to the document made after the fact. Please note, that we do not cover that particular aspect in this article series as it is optional within the process.
The sub structure rdv_customer_info_s in the above example contains the user attributes that describe the business key for a given point in time such as the load date timestamp. Note that this structure may contain multiple sub-objects, not just flattened attributes, as in this example.
Please further note that these descriptive data attributes change often over time in enterprise data; customers in the above example are free to change their email address or phone number, their gender, job and might marry therefore changing their last name as well as marital status. The number of children is updated on a frequent basis but even the birthdate of the customer might change. That being so, if for any reason, the source data was input incorrectly and these data quality issues have changed over time, the Data Vault satellite document should reflect those changes.
While an operational system would update the document, each change to the document should be versioned within a data warehouse. This is done in the Data Vault satellite document collection. Though, it is not necessary to perform delta-checks in this case, identifying actual changes to the source data based on the attributes of the target satellite. Instead, it is possible to simply load any source document into the satellite, thus accepting non-deltas. The only drawback to this process is that the satellite will consume more storage than necessary.
Since the satellite documents describe a business key, or a relationship between business keys, they are stored within the same MongoDB collection as the hub or link document and there is no additional document collection for satellite documents needed; represented as such:
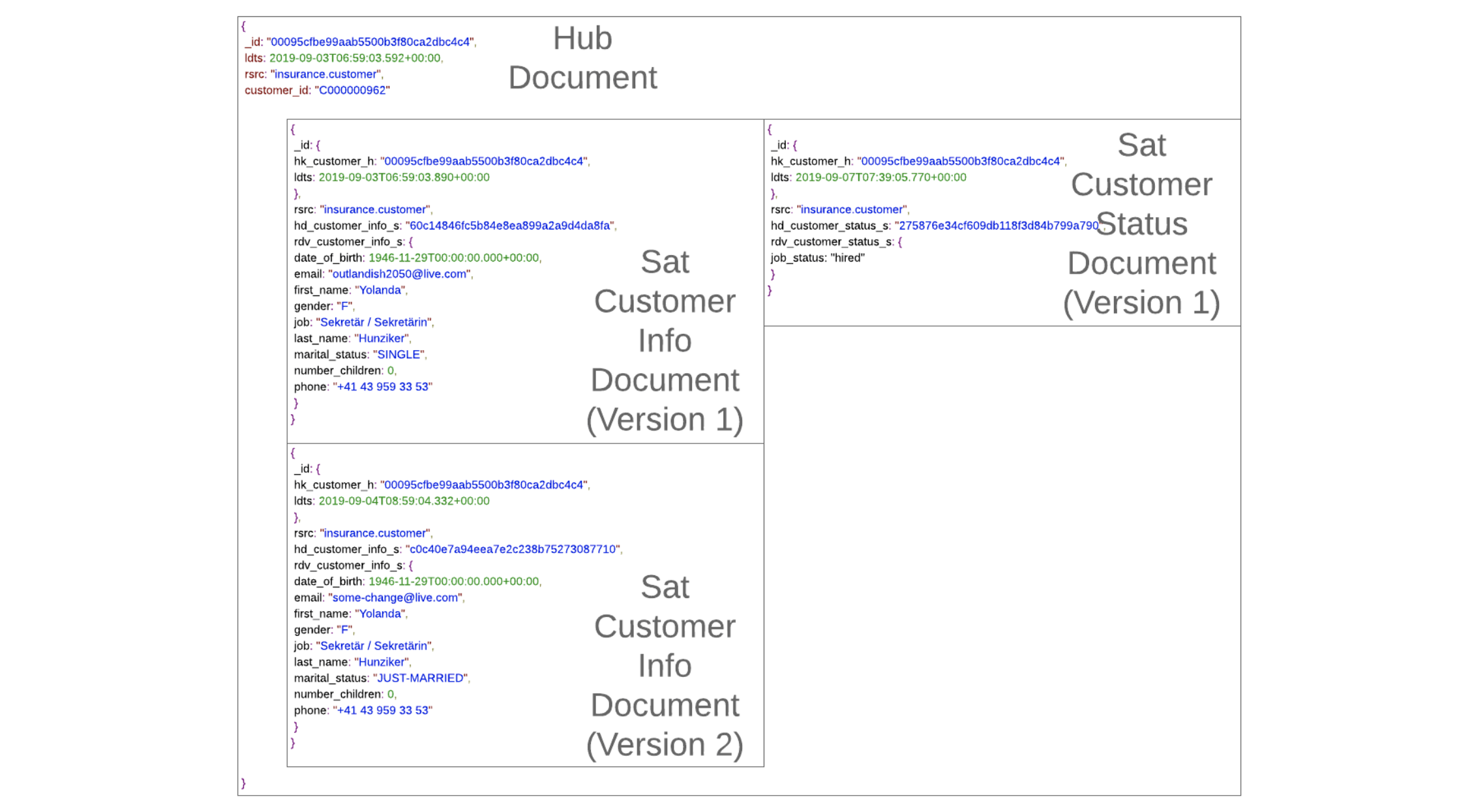
The above diagram illustrates the reason the name of the satellite structure is critical, as when a merge and flatten function is later used, it will merge the hub document, that being the business key, with the satellite documents, in this instance the descriptions.
Though, it is possible to flatten the attributes at a later time and retrieve a combined document with a business key, as well as all of its descriptions along with their accompanying versions from all satellites. The name of the satellite in the sub-structure ensures that duplicate attribute names, those of a first name from multiple source systems and therefore from multiple satellites, present no issue.
As to to load the satellite documents into the hub or link collection, the following set of operations are typically performed:

The loading process is straightforward: first, the descriptive data is sourced from the source collections, the structure of the target satellite is projected on the incoming set of document as to perform any satellite splits and then the data is inserted into the target, in some cases a hub or link, collection. Please note that what is not utilized in this instance is a delta-check which is optional and would be based on the hash diff.
The MongoDB source code for loading such a satellite is presented below:
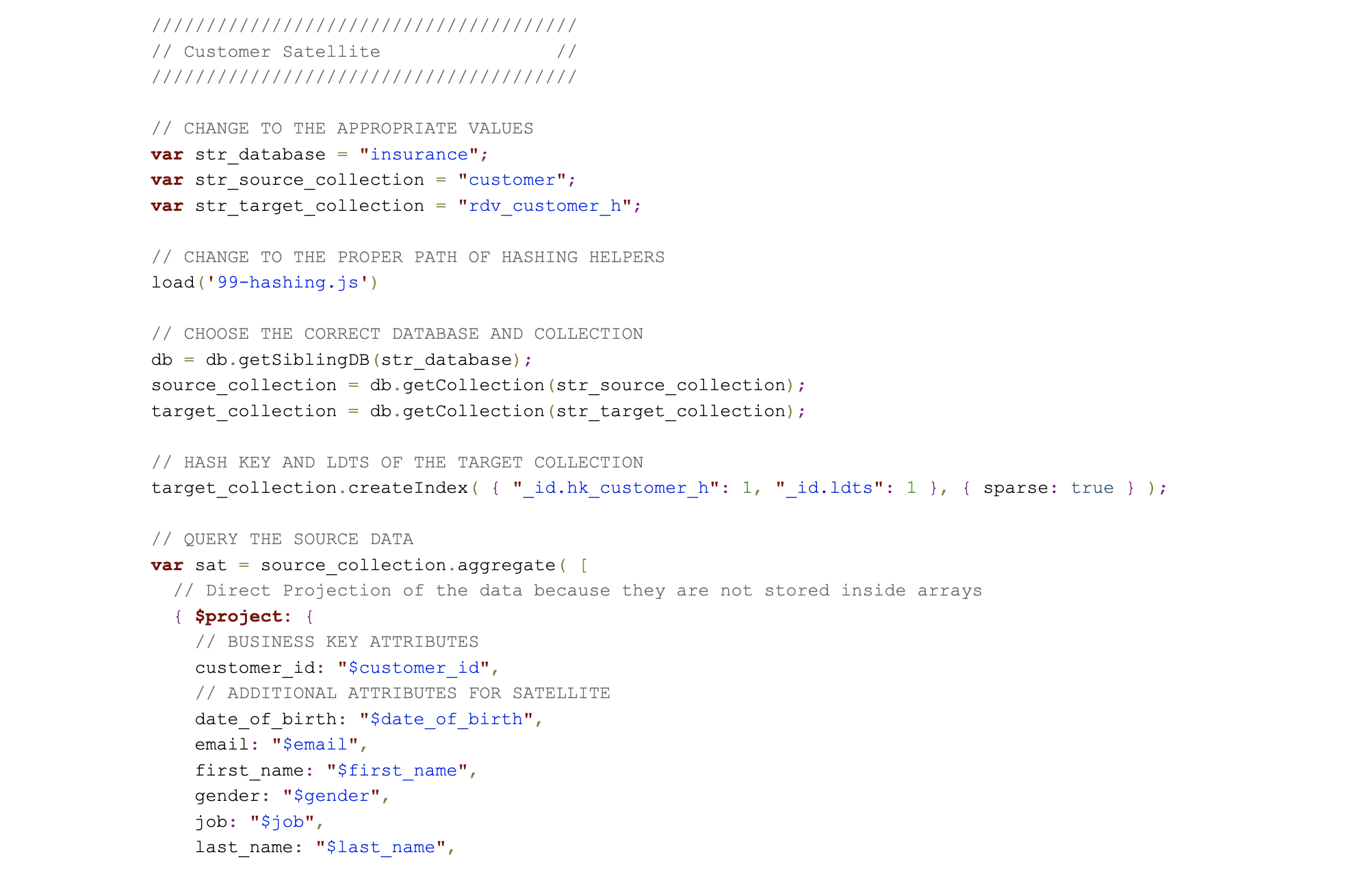
Again, while this script is calculating the hash diff value, it is not currently using it for any delta checks.
Thus, this completes our initial series on Data Vault on MongoDB. As we’ve written before, this work is from an ongoing project between Scalefree and MongoDB to fine-tune these statements made on a massive volume scale.
That being so, we are going to continue updating these articles in the near future. So, please get in touch with us for any updates made in the meantime. If you’d like to add any input into the above, feel free to leave a comment below.
Get Updates and Support
Please send inquiries and feature requests to [email protected].
For Data Vault training and on-site training inquiries, please contact [email protected] or register at www.scalefree.com.
To support the creation of Visual Data Vault drawings in Microsoft Visio, a stencil is implemented that can be used to draw Data Vault models. The stencil is available at www.visualdatavault.com.