The last article within our series recently covered the Data Vault hub entity which is used to capture distinct list of business keys in an enterprise data warehouse as most integration will actually occur on these hub entities themselves. However, there are scenarios in which the integration of data solely on these hub entities is not sufficient enough for the necessary end goal in mind.
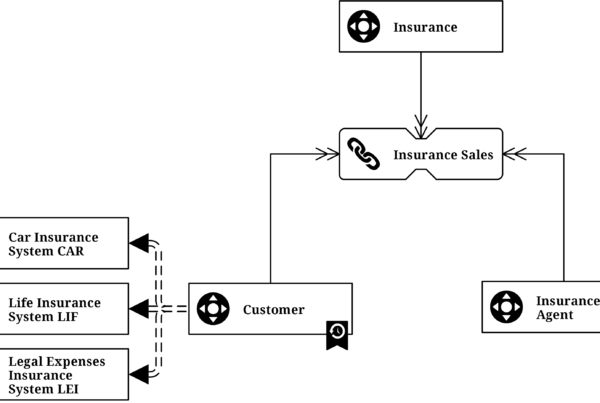
Consider this situation in which a sample data set, involving an insurance company, concerning customers signing car and home insurance policies as well as filing claims, each respectively. Though before moving forward with the example, it is important to note that there are relationships between the involved business keys, that of the customer number, the policy identifiers, and the claims.
These relationships are captured by Data Vault link entities and just like hubs, they contain a distinct list of records, as such, they contain no duplicates in terms of stored data. Thus, both will form the skeleton of Data Vault and later be described by descriptive user data stored in satellites.
Therefore the link implements the relationship by referencing all hubs that store the business keys involved in the relationship itself. To illustrate, the following diagram shows a Visual Data Vault diagram that shows that given relationship as implemented in a link:

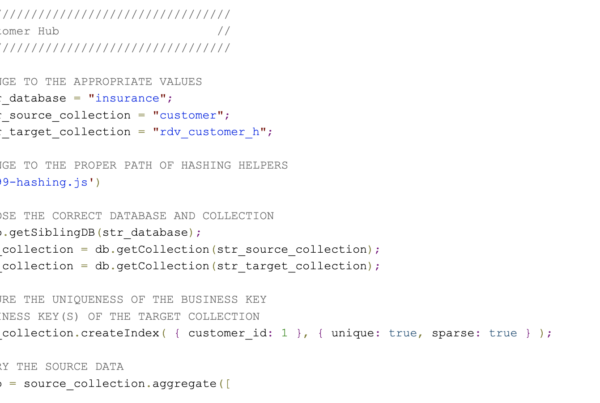
In MongoDB, a link entity is implemented in a document collection, just like the hub entity that was discussed in the last article as such:

That being so, the link structure contains the following objects that describe the relationship:
- The _id element identifies the link document though instead of relying on the MongoDB identifier, a hash value is calculated, e.g. a MD5 value, to uniquely identify the link entry beyond the MongoDB database.
- The ldts (load date timestamp) indicates when the link entry was identified by the enterprise data warehouse for the first time.
- The rsrc element indicates the source where the link entry has originated.
- The identifying hash keys of the referenced hub documents are contained in _ref
Within the loading process of the link document collection, the first step is to identify the relationships in the source document collection. Once the relationships are identified, the relationships are then loaded into the link document collection using the following process:

In MongoDB, this process is implemented using aggregation pipelines as discussed in an earlier article within this series. The code first filters for those customers that have a home insurance via $match. Then, the $unwind stage extracts the array of home insurances, i.e. an array with multiple values gets converted into individual documents. Duplicates are removed then via $group.
The following shows the code needed for loading a link document collection from a source collection, in the process of implementing the data flow described earlier. It can be executed in the MongoDB Shell, though it pays to note that it also uses the hashing function introduced in the previous article.

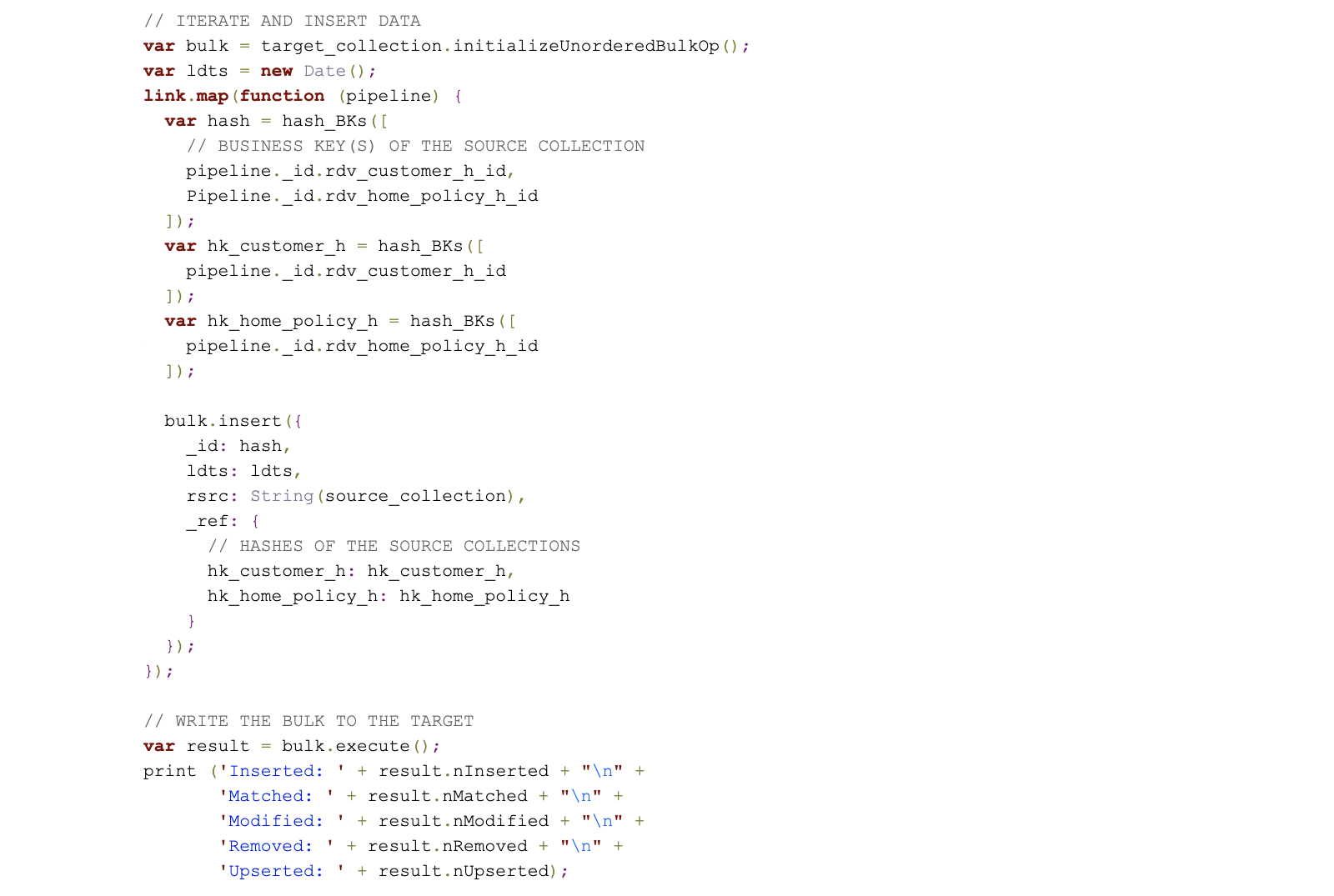
Please note that there are variations of this link structure, e.g. to capture transactions, which is then called a non-historized link, or line-items, e.g. from invoices and orders, in a degenerated link. To further this point, consider additional aspects of the claims, as they do not have unique business keys. To illustrate this point, while the link would capture the first transaction, such as a claim, it would not capture subsequent claims of the same policy. This is due to the fact that the link is a distinct list of business key relationships and once it finds the relationship between customer as well as the related home insurance policy, it will not load subsequent transactions.
This becomes an issue when providing transaction-based fact entities.
Typically, most users would like to have one fact record per transaction. Though to achieve this, we must modify the above link pattern in a way that makes it possible to load multiple transactions with the same hub document references.
This is achieved by adding an additional set of elements to the link document and then calculating the document ID though not simply from the referenced business keys alone but also from the additional element or elements. This approach will provide a unique document ID per transaction or event.
Though before going forward with this concept too much, let’s consider these special link entities in a subsequent post.
Please note that this work is from an ongoing project between Scalefree and MongoDB with the goal of fine-tuning these statements on a massive volume scale.
That being so, we are going to continue updating these articles in the near future.
To see the updated information as it is added, please check back by bookmarking this piece.
Questions? Comments?
We’d love to hear from you in the comment section below!
Get Updates and Support
Please send inquiries and feature requests to [email protected].
For Data Vault training and on-site training inquiries, please contact [email protected] or register at www.scalefree.com.
To support the creation of Visual Data Vault drawings in Microsoft Visio, a stencil is implemented that can be used to draw Data Vault models. The stencil is available at www.visualdatavault.com.