
An initial decision of critical importance within Data Vault development relates to the definition of naming conventions for database objects. As part of the development standardization, these conventions are mandatory as to maintain a well-structured and consistent Data Vault model. It is important to note that proper naming conventions boost usability of the data warehouse, not only for solution developers but also for power users within data exploration.
Throughout this article, we will present the most vital considerations within our standard book, the process of defining naming conventions.
Naming convention documentation
It is one aspect to simply define naming conventions utilized within the development of your data warehouse, but it is completely another to establish consistency as to create defined naming conventions that are to become standards. That said, it is a good practice to document a guideline for naming Data Warehouse objects. To that end, the next sections will discuss several considerations to take account of when defining the naming conventions for a data warehouse solution.
Letter case
There are several options when it comes to considering letter case for names: all uppercase, all lowercase, Camel Case, Pascal Case. Though the variances may be slight, each option does have its own advantages and disadvantages regarding legibility as well as type-ability, to briefly touch upon the differences.
Ultimately, the decision regarding letter case falls to the decision of which database management system is used as some, such as PostgreSQL, support case-sensitive object name which requires the use of quoted names. Therefore, users often prefer the lower-case by default in PostgreSQL as having lower-cased object names can reduce the amount of code that is to be generated while simultaneously improving the usability for ad-hoc queries by power users. Nevertheless, it is imperative to maintain one consistent letter case for both entity and column names.
Usage of underscores “_”, hyphens “-”
To improve readability, word separators like underscores “_” or, depending on use-cases, hyphens/dashes “-” are desirable. Though it is important to remember that in many systems, hyphens are interpreted as minus signs. That said, hyphens are commonly used in XML or JSON data format though they can be easily replaced by underscores, should the latter be used as separators.
Abbreviation, acronyms
Some systems enforce character limit on object names, e.g. Oracle 12.1 and below only allows for a maximum object name length of 30 bytes. Therefore, abbreviations and acronyms may be taken into consideration during the object naming process, despite the fact that they can often lead to misinterpretation. To combat this, it is suggested to compile a document containing a list of the abbreviations being used with detailed description of their meanings. However, to limit any possible confusion avoid excessive use of abbreviations and acronyms.
In logical models, it is advisable, that object names are as self-explanatory as possible, i.e. most words should be fully spelled out, except common abbreviations for longer words such as “dept” for “department” or “org” for “organisation”. However, abbreviations and acronyms are typically used in physical models, to keep object names short.
Singular vs. plural object names
It is a common practice to utilize nouns or noun phrases, in their singular form, as object name. This is done to avoid the necessity of dealing with irregular pluralization in English, e.g. man/men, person/people, which would unnecessarily add a whole new level of complexity within the data model.
Prefix vs. Suffix
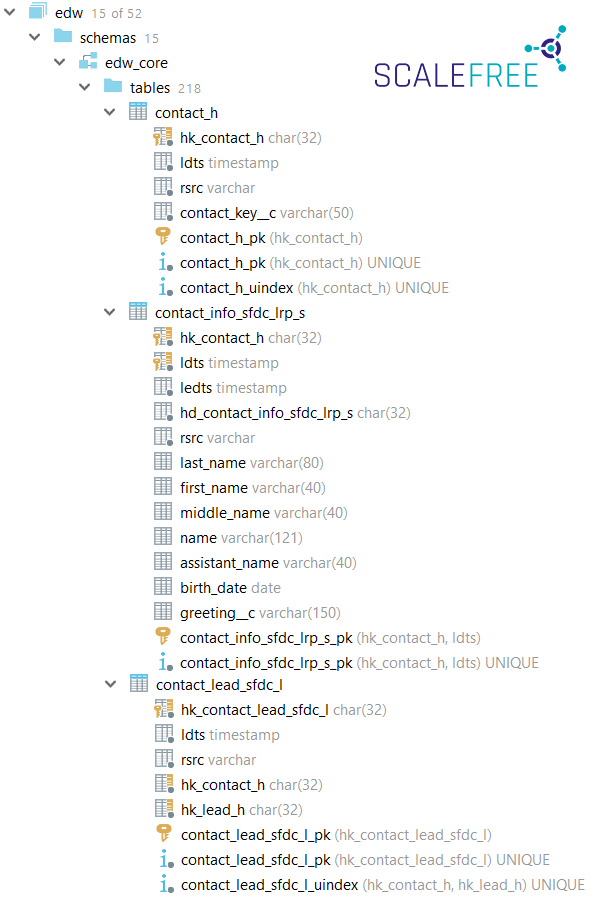
Whether objects are named using prefixes or suffixes, is not of much importance within the development. That said, internally at Scalefree, we prefer table names with suffixes such as “customer_h”, “transaction_l” instead of utilizing prefixes. The advantage of this method is, given most database tools sort tables alphabetically, all tables, which are related to a business object, will be grouped together. For example all contact hubs, satellites, and links that have names beginning with “contact_…” will, therefore, be found together in the browser. This supports data exploration by power users and developers.
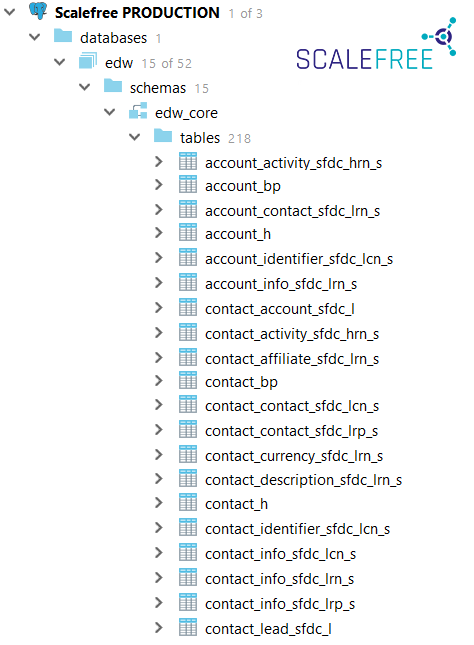
Nevertheless, prefixes can be meaningful within some use cases, e.g. using prefix in layer schema names helps keeping them neatly listed together in the database browser.
Conclusion
Naming conventions are partially a matter of personal preference and of organizational guidelines. Regardless, the more systematically consistent the naming conventions become when defined, the more benefits will ultimately be seen within the development and implementation of your Data Vault solution. To illustrate this point, we encourage Data Vault development teams to write and implement a simple SQL function that inspects the entire database while checking for naming convention inconsistencies. This further ensures that standards are being followed.
Interested in how we standardize naming conventions here at Scalefree? In an upcoming article, we will share several concrete suggestions for naming conventions, most of which both our customers and our team regularly utilize internally.
Now let’s open this up for discussion in the comment box below: How do you implement naming conventions within your Data Vault development? What conventions do you follow?
Get Updates and Support
Please send inquiries and feature requests to [email protected].
For Data Vault training and on-site training inquiries, please contact [email protected] or register at www.scalefree.com.
To support the creation of Visual Data Vault drawings in Microsoft Visio, a stencil is implemented that can be used to draw Data Vault models. The stencil is available at www.visualdatavault.com.


Thank you for your comment Arne!
Kind regards,
Your Scalefree Team
At ChipSoft we use an ORM to generate the tables for our data warehouse product. Definition is done in C#, so casing follows C# conventions (=PascalCase).
We use database schema’s as datastores (being security boundaries). We have not enough of them yet to prescribe a naming standard.
For the table names in Data Vault we also prefer postfixing, for the same grouping argument you also use.
The format of a Hub-table name would be {module}{entity}Hub, e.g. ConfigUserHub, e.g. ConfigUserHub.
The corresponding Satellite-tables would have names like {module}{entity}{optional subdivision}Sat, e.g. ConfigUserSat or ConfigUserPersonalDataSat.
The Link-tables would have names like ConfigUserLink and ConfigUserOrganisationalLink.
In this way, tables will first be grouped per module, and next per entity, which we think is convenient.
For Information marts (dimensional modelled) we use prefixing, because Dimension-tables are not necessarily bound to a single Fact-table.
The format of Dimension-table names is: Dim{optional subject area}[entity}.
The format of Fact-table names is: Fact{subject area}{measure group}.
For Fact-tables (as well as Data Vault Bridge-tables) we use often plural forms. All other table names use singular forms.
Thank you for your comment Arne!
Assume you have a source system in english, but your users speak german. Additionaly the column names from the source system are highly abbreviated, while your users require speaking column names in their reports. What is the better strategy to name the columns in the raw vault? On one hand you could follow the data driven approach and therefore use the table and column names from the source system. The advantage here is to deliver results quickly. On the other hand you could follow the business centered approach and have german and speaking column names in the raw vault. The advantage would be that you find requested data faster and don’t have to rename columns on the way to reporting. What is the better approach from your experience?
Hello Daniel,
Thank you for reaching out with your question! Generally it is a good idea to position translation work further downstream (i.e. Business Vault, preferably even Information Delivery), in order to achieve the advantage that you mentioned – to deliver results rapidly. Moreover, if an attribute is renamed in the source, you won’t have to propagate the column rename through the Raw/Business Vault.
However, if for example you have to process a source system that is in a completely foreign language to your organisation, you might want to have translation work done earlier in the pipeline, either in the Raw Vault, or in the Staging area. This ensures that you get needed data into your data warehouse in a comprehensible state for all users – both developers and data consumers.
Thank you kindly,
Trung Ta