
Within Data Vault there are special entities which leverage the query performance on the way out of the Data Vault. These entities are placed between the Data Vault and the Information Delivery Layer and are necessary for instances in which many joins and aggregations on the Raw Data Vault are executed what cause performance issues. This often happens when designing the virtualized fact tables in the information and data marts. Thus, to produce the required granularity in the fact tables without increasing the query time, Bridge tables come into play. Bridge tables belong to the Business Vault and have the purpose of improving performance, similar in manner to the PIT table which was discussed in a prior newsletter.
As a means to achieve its goals, the bridge table materializes the grain shift that is often required within the information delivery process. Though, before we dig deeper into the specifics of using a bridge table for performance tuning, it is important to first define granularities within a data warehouse.
Grain Definitions in Data Warehousing
The grain within a dimensional model is the level of detail available of each table. Thus, the grain of a fact table is defined by the number of related dimensions. Basically, there are three different types of granularities for fact entities within a dimensional model.
The first is the transaction fact table which corresponds to a measurement event at a given point within space and time. The fact tables contain a foreign key for each related dimension and optionally precise timestamps as well as degenerate dimension keys. It then becomes apparent that the grain of the transaction fact table is the grain of the transaction itself.
The second one is the period snapshot fact table. The periodic snapshot grain is a standard period, as it summarizes measurement events over a given period which at times can be a day, week, etc. That said, it is more often used to capture warehouse data, such as product levels per day. For example, a snapshot of product levels will be generated on a daily basis, thus the name.
Thirdly, accumulating snapshot fact tables are similar in nature to periodic snapshot tables. However, as opposed to reporting the data within a given time frame, only the deltas are reported after the initial snapshot. For example, within a fact entity describing warehouse stock levels, the first initial load of all products would be contained within the first snapshot. After that initial snapshot, only the deltas, those of the incoming and outgoing products, would be found in the subsequent snapshots. Thus, to find the current warehouse levels of a given day, all data until the given day would need to be aggregated.
Comparison to Data Vault 2.0
Within Data Vault, Raw Data Vault link entities always contain the finest possible grain what is the grain coming from the source. This is due to the fact that the Raw Data Vault captures the original granularity from the source system without any aggregations applied during data loading. Within the information delivery, there often exists a target granularity, which is defined by requirements of the business. In many cases, this target granularity cannot be found directly within the Data Vault model. Therefore, this granularity must be derived from the granularity of the Data Vault model.
The bridge table acts as a higher-level fact-less fact table and contains hash keys from the hubs and links it spans. Another performance improvement can be achieved by moving resource intensive computations to the bridge table. This is especially important when creating virtual information marts on the Data Vault because these require some computing which slows down the access to the virtualized information mart entities. Using bridge tables, the query performance can be drastically improved. Bridge tables are not required to have the same grain as the links that they are covering. In these cases, the bridge table might contain aggregated values that are added to the structure and loaded using GROUP BY statements. The resulting bridge table has a higher grain than the links that are included in the table.
Common business examples for a grain shift in a transaction fact table are based on invoices. In the given example, an information mart is needed by the business user, that contains invoices in the fact table. In most cases, invoices consist of line items (known as dependent child key) and it is those line items that would be stored in the Raw Data Vault, which would result in a finer grain than in the target fact table. Though, to reach the desired level of detail, the line items need to be aggregated to invoices.
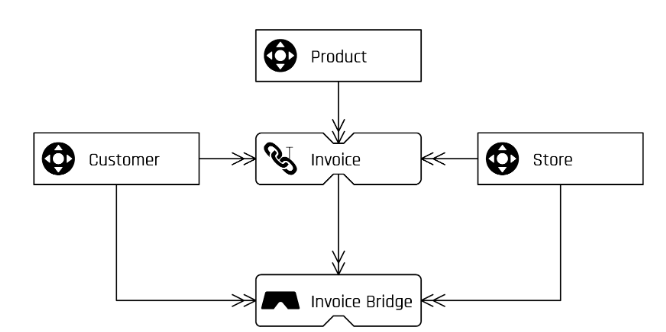
Here, the non-historized link becomes very helpful as a transaction fact table can be typically derived from the non-historized links. If they store the original grain of the transaction and if it equals the target grain, no further aggregations are needed. In our example of the invoices, a higher grain is needed for the transaction fact table. To receive a better performance, a bridge table would be needed, which materializes the grain shift.
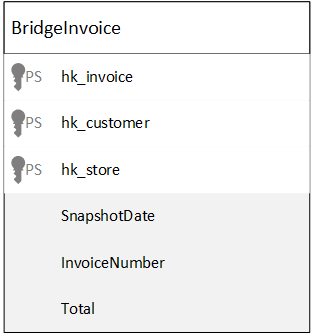

The grain of the shown bridge table is defined by the hub references. Additionally, the bridge table contains link hash keys and it is with these, link satellites can be joined from the bridge to access descriptive attributes. Additional measure attributes store the results of aggregations. The last attribute of the bridge table is the snapshot date, which is added by the loading procedure. In some cases, the snapshot data can be part of the primary key, for example accumulating sales tracking. In this case the sales are tracked per customer, per store, per (snapshot-) day. The following example shows an example of a Bridge load.
SELECT
hk_invoice,
hk_customer,
hk_store,
? as SnapshotDate,
InvoiceNumber,
SUM(Total)
FROM Link_Invoice inv
WHERE NOT EXISTS (
SELECT
1
FROM
DataVault.biz.BridgeInvoice tgt
WHERE
inv.hk_invoice = tgt.hk_invoice AND
inv.hk_customer = tgt.hk_customer AND
inv.hk_store = tgt.hk_store AND
inv.SnapshotDate = tgt.SnapshotDate
)
GROUP BY hk_invoice, hk_customer, hk_store,SnapshotDate,InvoiceNumber;
‘?’ is a parameter which is set to the snapshot date. For example to 6 am by a daily bridge load.
Conclusion
This article introduced a Data Vault entity that is essential when it comes to grain shifts within the information delivery. With the bridge table, grain shifts can be materialized to boost performance for the required aggregations and join operations. The above dealt with different grain definitions for fact tables and discussed the transactional fact table in higher detail.
The business example showed how such a table will appear and how to build it. As there are two more definitions of grain for fact tables according to Kimball, how the periodic snapshot fact tables as well as the accumulating snapshot fact tables grain will be discussed in a future article.
Get Updates and Support
Please send inquiries and feature requests to [email protected].
For Data Vault training and on-site training inquiries, please contact [email protected] or register at www.scalefree.com.
To support the creation of Visual Data Vault drawings in Microsoft Visio, a stencil is implemented that can be used to draw Data Vault models. The stencil is available at www.visualdatavault.com.

The example is a poor one as any Dimensional mart should contain the Fact Order_Line.
Really? What about the user complaints table? 😉
I think your query is incorrect. Group by should have all the keys that are in the select clause. Correct? But that is not my question. My question is do we have any rules in creating an aggregate bridge on what to group by and what not to?
Hello, Author! I can’t figure out how the Invoice link can be related to the Product hub (Figure 1)? If your Invoice link table contains hash key from Product hub table than it is not Invoice but InvoiceItem and if this is so than Invoice bridge can’t be aggregated by Invoice (number) – the model breaks down. Please help me to figure it out 🙂
Hi Andrey,
You are right. Thanks for the feedback. The Non-Historized Link should contain the term “line_item” as it relates to the Product Hub. The GROUP BY statement also has to contain the snapshot date, the store Hashkey, the Customer Hashkey as well as the Invoice Number. We will correct this.
– Marc